Base de connaissances
La base de connaissances vous permet de télécharger, traiter et rechercher vos documents grâce à une recherche vectorielle intelligente et au découpage en segments. Les documents de différents types sont automatiquement traités, intégrés et rendus consultables. Vos documents sont intelligemment segmentés, et vous pouvez les visualiser, les modifier et les rechercher à l'aide de requêtes en langage naturel.
Téléchargement et traitement
Il vous suffit de télécharger vos documents pour commencer. Ekinox les traite automatiquement en arrière-plan, extrayant le texte, créant des embeddings et les divisant en segments consultables.
Le système gère l'ensemble du processus de traitement pour vous :
- Extraction de texte : Le contenu est extrait de vos documents à l'aide d'analyseurs spécialisés pour chaque type de fichier
- Segmentation intelligente : Les documents sont divisés en segments significatifs avec une taille et un chevauchement configurables
- Génération d'embeddings : Des embeddings vectoriels sont créés pour les capacités de recherche sémantique
- État du traitement : Suivez la progression du traitement de vos documents
Types de fichiers pris en charge
Ekinox prend en charge les fichiers PDF, Word (DOC/DOCX), texte brut (TXT), Markdown (MD), HTML, Excel (XLS/XLSX), PowerPoint (PPT/PPTX) et CSV. Les fichiers peuvent atteindre jusqu'à 100 Mo chacun, avec des performances optimales pour les fichiers de moins de 50 Mo. Vous pouvez télécharger plusieurs documents simultanément, et les fichiers PDF bénéficient d'un traitement OCR pour les documents numérisés.
Visualisation et modification des segments
Une fois vos documents traités, vous pouvez visualiser et modifier les segments individuels. Cela vous donne un contrôle total sur l'organisation et la recherche de votre contenu.
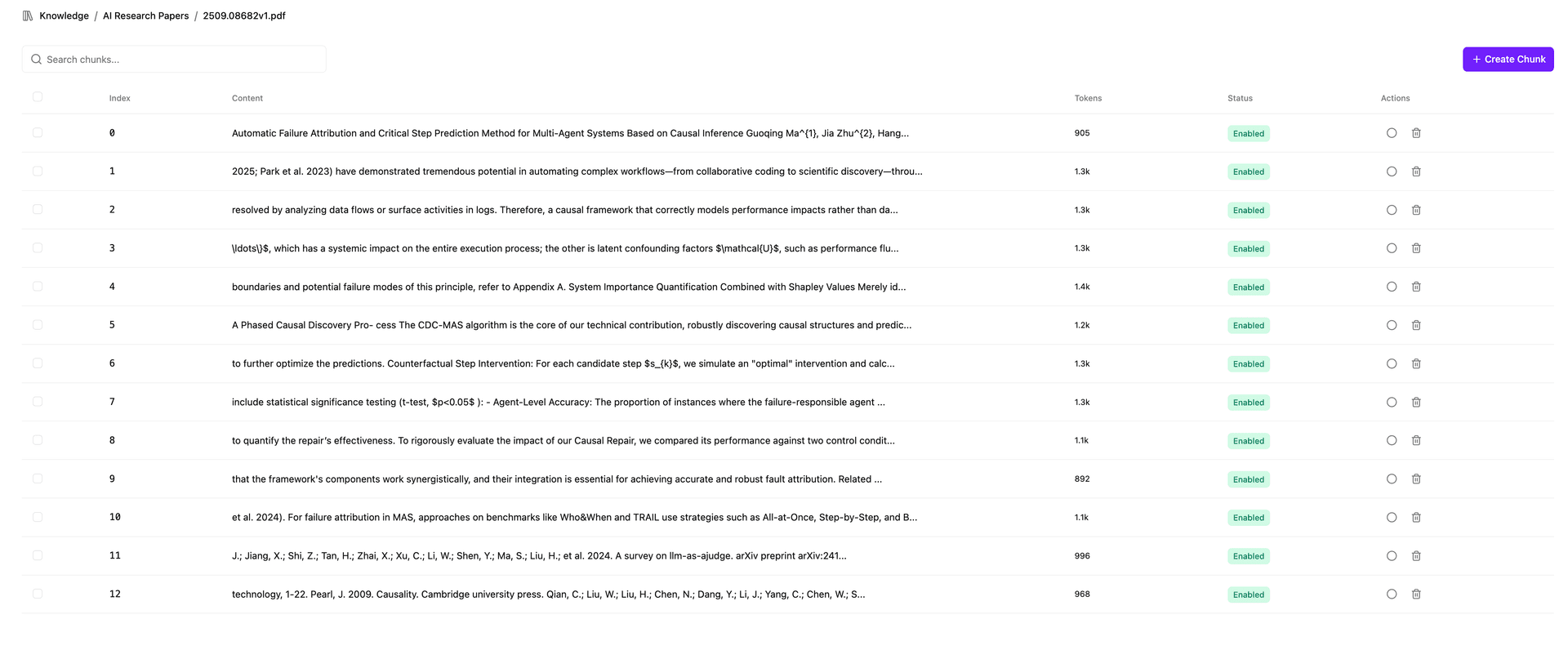
Configuration des fragments
- Taille par défaut des fragments : 1 024 caractères
- Plage configurable : 100 à 4 000 caractères par fragment
- Chevauchement intelligent : 200 caractères par défaut pour préserver le contexte
- Découpage hiérarchique : respecte la structure du document (sections, paragraphes, phrases)
Capacités d'édition
- Modifier le contenu des fragments : modifier le contenu textuel des fragments individuels
- Ajuster les limites des fragments : fusionner ou diviser les fragments selon les besoins
- Ajouter des métadonnées : enrichir les fragments avec du contexte supplémentaire
- Opérations en masse : gérer efficacement plusieurs fragments
Traitement avancé des PDF
Pour les documents PDF, Ekinox offre des capacités de traitement améliorées :
Support OCR
Lorsque configuré avec Azure ou Mistral OCR :
- Traitement de documents numérisés : extraction de texte à partir de PDF basés sur des images
- Gestion de contenu mixte : traitement des PDF contenant à la fois du texte et des images
- Haute précision : les modèles d'IA avancés assurent une extraction précise du texte
Utilisation du bloc de connaissances dans les flux de travail
Une fois vos documents traités, vous pouvez les utiliser dans vos flux de travail d'IA grâce au bloc de connaissances. Cela permet la génération augmentée par récupération (RAG), permettant à vos agents IA d'accéder et de raisonner sur le contenu de vos documents pour fournir des réponses plus précises et contextuelles.
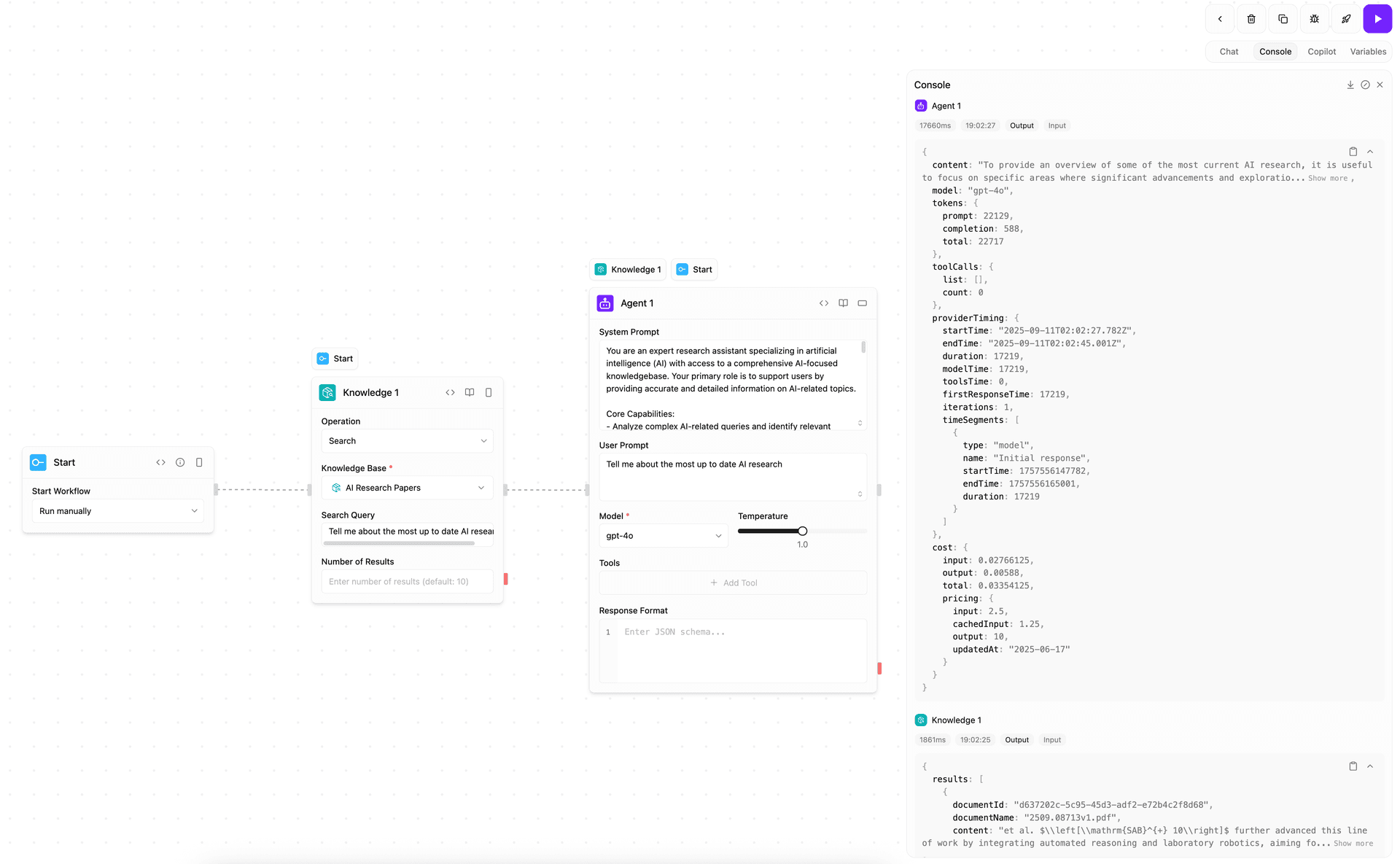
Fonctionnalités du bloc de connaissances
- Recherche sémantique : trouver du contenu pertinent à l'aide de requêtes en langage naturel
- Intégration du contexte : inclure automatiquement les fragments pertinents dans les prompts des agents
- Récupération dynamique : la recherche s'effectue en temps réel pendant l'exécution du flux de travail
- Évaluation de la pertinence : résultats classés par similarité sémantique
Options d'intégration
- Prompts système : fournir du contexte à vos agents IA
- Contexte dynamique : rechercher et inclure des informations pertinentes pendant les conversations
- Recherche multi-documents : interroger l'ensemble de votre base de connaissances
- Recherche filtrée : combiner avec des tags pour une récupération précise du contenu
Technologie de recherche vectorielle
Ekinox utilise la recherche vectorielle alimentée par pgvector pour comprendre le sens et le contexte de votre contenu :
Compréhension sémantique
- Recherche contextuelle : trouve du contenu pertinent même lorsque les mots-clés exacts ne correspondent pas
- Récupération basée sur les concepts : comprend les relations entre les idées
- Prise en charge multilingue : fonctionne dans différentes langues
- Reconnaissance des synonymes : trouve des termes et concepts associés
Capacités de recherche
- Requêtes en langage naturel : posez des questions en français courant
- Recherche par similarité : trouvez du contenu conceptuellement similaire
- Recherche hybride : combine la recherche vectorielle et la recherche traditionnelle par mots-clés
- Résultats configurables : contrôlez le nombre et le seuil de pertinence des résultats
Gestion documentaire
Fonctionnalités d'organisation
- Téléchargement en masse : téléchargez plusieurs fichiers à la fois via l'API asynchrone
- État de traitement : mises à jour en temps réel sur le traitement des documents
- Recherche et filtrage : trouvez rapidement des documents dans de grandes collections
- Suivi des métadonnées : capture automatique des informations de fichier et des détails de traitement
Sécurité et confidentialité
- Stockage sécurisé : documents stockés avec une sécurité de niveau entreprise
- Contrôle d'accès : autorisations basées sur l'espace de travail
- Isolation du traitement : chaque espace de travail dispose d'un traitement de documents isolé
- Conservation des données : configurez les politiques de conservation des documents
Premiers pas
- Accédez à votre base de connaissances : accessible depuis la barre latérale de votre espace de travail
- Téléchargez des documents : glissez-déposez ou sélectionnez des fichiers à télécharger
- Surveillez le traitement : observez le traitement et le découpage des documents
- Explorez les fragments : visualisez et modifiez le contenu traité
- Ajoutez aux flux de travail : utilisez le bloc Connaissances pour l'intégrer à vos agents IA
La base de connaissances transforme vos documents statiques en une ressource intelligente et consultable que vos flux de travail IA peuvent exploiter pour des réponses plus informées et contextuelles.