Guardrails
El bloque Guardrails valida y protege tus flujos de trabajo de IA comprobando el contenido contra múltiples tipos de validación. Asegura la calidad de los datos, previene alucinaciones, detecta información personal identificable (PII) y aplica requisitos de formato antes de que el contenido avance por tu flujo de trabajo.
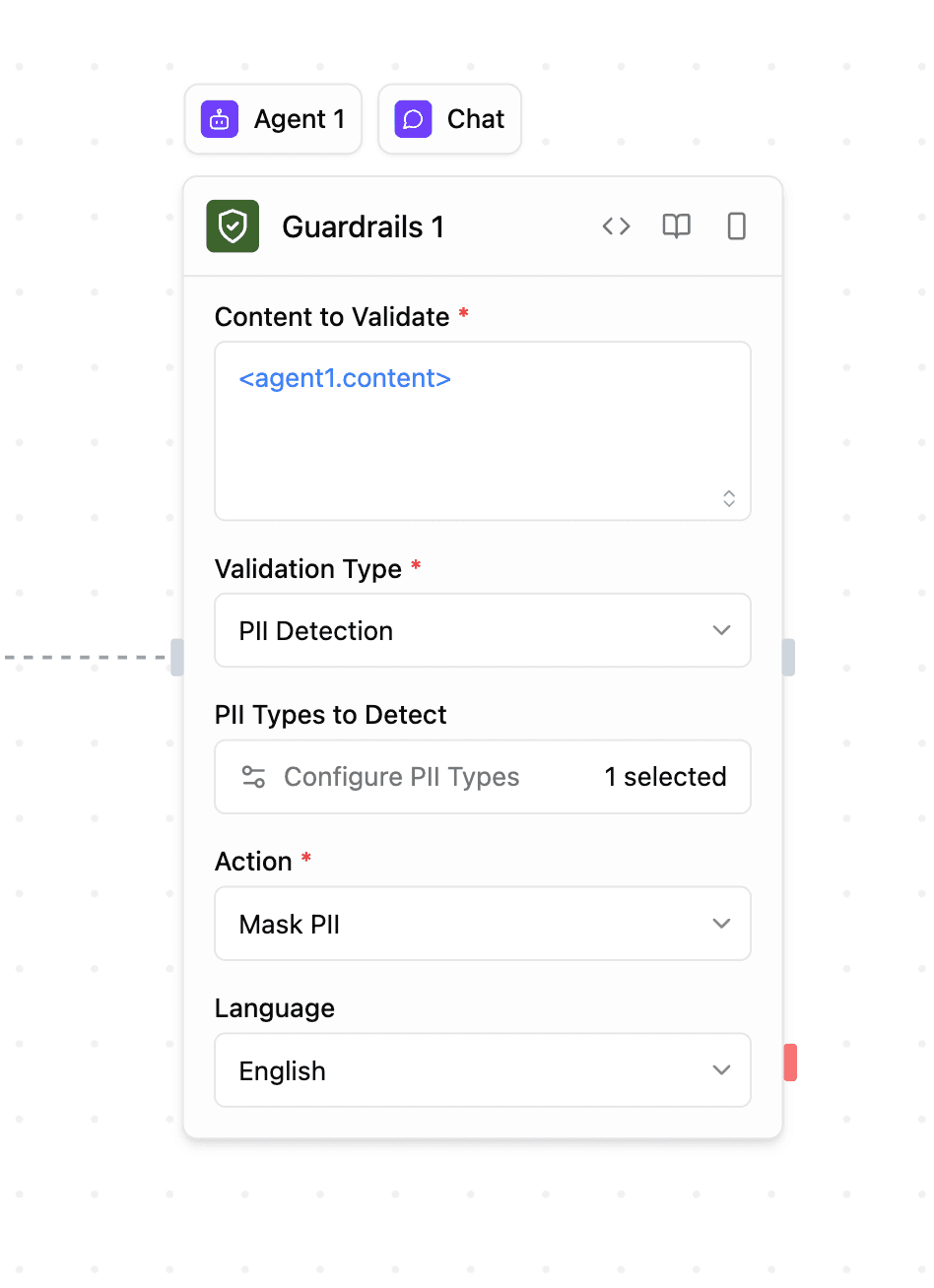
Descripción general
El bloque Guardrails te permite:
Validar estructura JSON: Asegura que las salidas de LLM sean JSON válido antes de analizarlas
Coincidir con patrones Regex: Verifica que el contenido coincida con formatos específicos (correos electrónicos, números de teléfono, URLs, etc.)
Detectar alucinaciones: Utiliza puntuación RAG + LLM para validar las salidas de IA contra el contenido de la base de conocimientos
Detectar PII: Identifica y opcionalmente enmascara información personal identificable en más de 40 tipos de entidades
Tipos de validación
Validación JSON
Valida que el contenido tenga un formato JSON adecuado. Perfecto para garantizar que las salidas estructuradas de LLM puedan analizarse de forma segura.
Casos de uso:
- Validar respuestas JSON de bloques Agent antes de analizarlas
- Asegurar que las cargas útiles de API estén correctamente formateadas
- Comprobar la integridad de datos estructurados
Output:
passed:truesi es JSON válido,falseen caso contrarioerror: Mensaje de error si la validación falla (p. ej., "JSON inválido: Token inesperado...")
Validación Regex
Comprueba si el contenido coincide con un patrón de expresión regular especificado.
Casos de uso:
- Validar direcciones de correo electrónico
- Comprobar formatos de números de teléfono
- Verificar URLs o identificadores personalizados
- Aplicar patrones de texto específicos
Configuración:
- Patrón Regex: La expresión regular para comparar (p. ej.,
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$para correos electrónicos)
Output:
passed:truesi el contenido coincide con el patrón,falseen caso contrarioerror: Mensaje de error si la validación falla
Detección de alucinaciones
Utiliza generación aumentada por recuperación (RAG) con puntuación de LLM para detectar cuando el contenido generado por IA contradice o no está fundamentado en tu base de conocimientos.
Cómo funciona:
- Consulta tu base de conocimientos para obtener contexto relevante
- Envía tanto la salida de la IA como el contexto recuperado a un LLM
- El LLM asigna una puntuación de confianza (escala de 0-10)
- 0 = Alucinación completa (totalmente infundada)
- 10 = Completamente fundamentado (totalmente respaldado por la base de conocimientos)
- La validación se aprueba si la puntuación ≥ umbral (predeterminado: 3)
Configuración:
- Base de conocimientos: Selecciona entre tus bases de conocimientos existentes
- Modelo: Elige LLM para puntuación (requiere razonamiento sólido - se recomienda GPT-4o, Claude 3.7 Sonnet)
- Clave API: Autenticación para el proveedor LLM seleccionado (oculta automáticamente para modelos alojados/Ollama)
- Umbral de confianza: Puntuación mínima para aprobar (0-10, predeterminado: 3)
- Top K (Avanzado): Número de fragmentos de la base de conocimientos a recuperar (predeterminado: 10)
Output:
passed:truesi la puntuación de confianza ≥ umbralscore: Puntuación de confianza (0-10)reasoning: Explicación del LLM para la puntuaciónerror: Mensaje de error si la validación falla
Casos de uso:
- Validar respuestas de agentes contra documentación
- Asegurar que las respuestas de atención al cliente sean precisas
- Verificar que el contenido generado coincida con el material de origen
- Control de calidad para aplicaciones RAG
Detección de PII
Detecta información de identificación personal utilizando Microsoft Presidio. Compatible con más de 40 tipos de entidades en múltiples países e idiomas.
Cómo funciona:
- Escanea el contenido en busca de entidades PII mediante coincidencia de patrones y PNL
- Devuelve las entidades detectadas con ubicaciones y puntuaciones de confianza
- Opcionalmente enmascara la PII detectada en la salida
Configuración:
- Tipos de PII a detectar: Seleccione de categorías agrupadas mediante selector modal
- Común: Nombre de persona, Email, Teléfono, Tarjeta de crédito, Dirección IP, etc.
- EE.UU.: SSN, Licencia de conducir, Pasaporte, etc.
- Reino Unido: Número NHS, Número de seguro nacional
- España: NIF, NIE, CIF
- Italia: Código fiscal, Licencia de conducir, Código de IVA
- Polonia: PESEL, NIP, REGON
- Singapur: NRIC/FIN, UEN
- Australia: ABN, ACN, TFN, Medicare
- India: Aadhaar, PAN, Pasaporte, Número de votante
- Modo:
- Detectar: Solo identificar PII (predeterminado)
- Enmascarar: Reemplazar PII detectada con valores enmascarados
- Idioma: Idioma de detección (predeterminado: inglés)
Salida:
passed:falsesi se detectan los tipos de PII seleccionadosdetectedEntities: Array de PII detectada con tipo, ubicación y confianzamaskedText: Contenido con PII enmascarada (solo si modo = "Mask")error: Mensaje de error si la validación falla
Casos de uso:
- Bloquear contenido que contiene información personal sensible
- Enmascarar PII antes de registrar o almacenar datos
- Cumplimiento con GDPR, HIPAA y otras regulaciones de privacidad
- Sanear entradas de usuario antes del procesamiento
Configuración
Contenido a validar
El contenido de entrada para validar. Esto típicamente proviene de:
- Salidas de bloques de agente:
<agent.content> - Resultados de bloques de función:
<function.output> - Respuestas de API:
<api.output> - Cualquier otra salida de bloque
Tipo de validación
Elija entre cuatro tipos de validación:
- JSON válido: Comprobar si el contenido es JSON correctamente formateado
- Coincidencia Regex: Verificar si el contenido coincide con un patrón regex
- Comprobación de alucinaciones: Validar contra base de conocimiento con puntuación LLM
- Detección de PII: Detectar y opcionalmente enmascarar información de identificación personal
Salidas
Todos los tipos de validación devuelven:
<guardrails.passed>: Booleano que indica si la validación fue exitosa<guardrails.validationType>: El tipo de validación realizada<guardrails.input>: La entrada original que fue validada<guardrails.error>: Mensaje de error si la validación falló (opcional)
Salidas adicionales por tipo:
Verificación de alucinaciones:
<guardrails.score>: Puntuación de confianza (0-10)<guardrails.reasoning>: Explicación del LLM
Detección de PII:
<guardrails.detectedEntities>: Array de entidades PII detectadas<guardrails.maskedText>: Contenido con PII enmascarado (si el modo = "Mask")
Ejemplos de casos de uso
Validar JSON antes de analizarlo
Escenario: Asegurar que la salida del agente sea JSON válido
- El agente genera una respuesta JSON estructurada
- Guardrails valida el formato JSON
- El bloque de condición verifica
<guardrails.passed> - Si pasa → Analizar y usar datos, Si falla → Reintentar o manejar el error
Prevenir alucinaciones
Escenario: Validar respuestas de atención al cliente
- El agente genera una respuesta a la pregunta del cliente
- Guardrails verifica contra la base de conocimientos de documentación de soporte
- Si la puntuación de confianza ≥ 3 → Enviar respuesta
- Si la puntuación de confianza < 3 → Marcar para revisión humana
Bloquear PII en entradas de usuario
Escenario: Sanear contenido enviado por usuarios
- El usuario envía un formulario con contenido de texto
- Guardrails detecta PII (correos electrónicos, números de teléfono, SSN, etc.)
- Si se detecta PII → Rechazar el envío o enmascarar datos sensibles
- Si no hay PII → Procesar normalmente
Validar formato de correo electrónico
Escenario: Comprobar el formato de dirección de correo electrónico
- El agente extrae el correo electrónico del texto
- Guardrails valida con un patrón regex
- Si es válido → Usar el correo electrónico para notificación
- Si no es válido → Solicitar corrección
Mejores prácticas
- Encadena con bloques de Condición: Usa
<guardrails.passed>para ramificar la lógica del flujo de trabajo según los resultados de validación - Usa validación JSON antes de analizar: Siempre valida la estructura JSON antes de intentar analizar las salidas de LLM
- Elige los tipos de PII apropiados: Selecciona solo los tipos de entidades PII relevantes para tu caso de uso para un mejor rendimiento
- Establece umbrales de confianza razonables: Para la detección de alucinaciones, ajusta el umbral según tus requisitos de precisión (más alto = más estricto)
- Usa modelos potentes para la detección de alucinaciones: GPT-4o o Claude 3.7 Sonnet proporcionan una puntuación de confianza más precisa
- Enmascara PII para el registro: Usa el modo "Mask" cuando necesites registrar o almacenar contenido que pueda contener PII
- Prueba patrones regex: Valida tus patrones de expresiones regulares minuciosamente antes de implementarlos en producción
- Monitorea fallos de validación: Rastrea los mensajes
<guardrails.error>para identificar problemas comunes de validación
La validación de Guardrails ocurre de forma sincrónica en tu flujo de trabajo. Para la detección de alucinaciones, elige modelos más rápidos (como GPT-4o-mini) si la latencia es crítica.