Parallel
Der Parallel-Block ist ein Container-Block in Ekinox, der es ermöglicht, mehrere Instanzen von Blöcken gleichzeitig auszuführen, um Workflows schneller zu verarbeiten.
Der Parallel-Block unterstützt zwei Arten der gleichzeitigen Ausführung:
Parallel-Blöcke sind Container-Knoten, die ihre Inhalte mehrfach gleichzeitig ausführen, im Gegensatz zu Schleifen, die sequentiell ausgeführt werden.
Überblick
Der Parallel-Block ermöglicht es dir:
Arbeit zu verteilen: Mehrere Elemente gleichzeitig zu verarbeiten
Ausführung zu beschleunigen: Unabhängige Operationen gleichzeitig auszuführen
Massenoperationen zu bewältigen: Große Datensätze effizient zu verarbeiten
Ergebnisse zu aggregieren: Ausgaben aus allen parallelen Ausführungen zu sammeln
Konfigurationsoptionen
Parallel-Typ
Wähle zwischen zwei Arten der parallelen Ausführung:
Anzahlbasierte Parallelität - Führe eine feste Anzahl paralleler Instanzen aus:
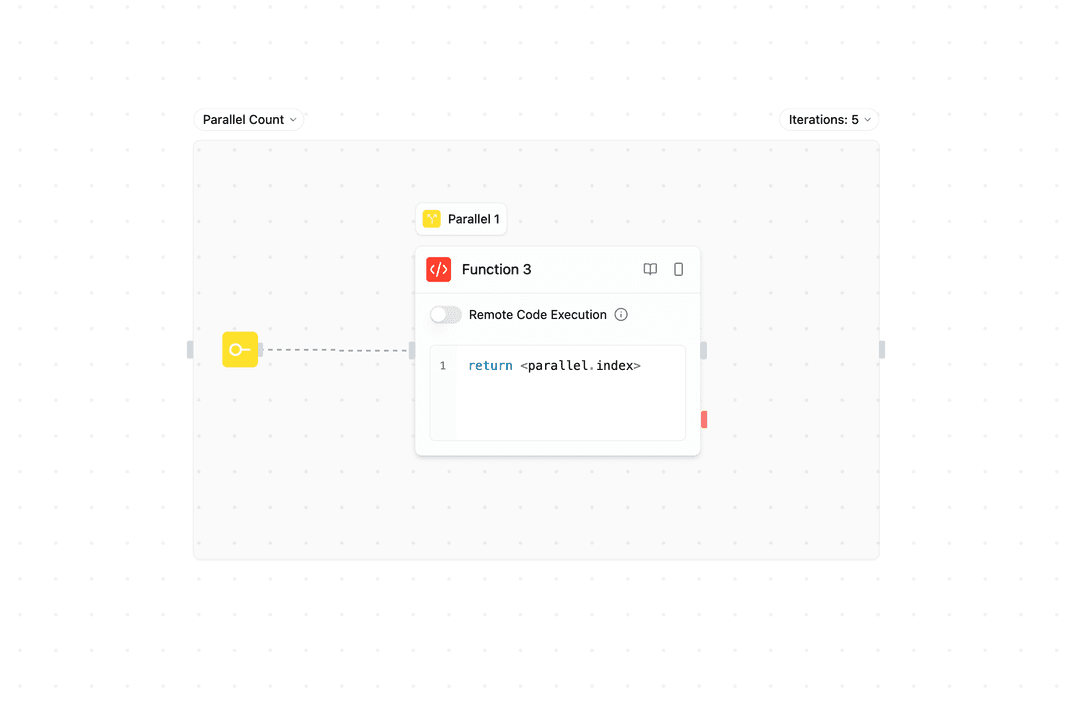
Verwende dies, wenn du dieselbe Operation mehrmals gleichzeitig ausführen musst.
Example: Run 5 parallel instances
- Instance 1 ┐
- Instance 2 ├─ All execute simultaneously
- Instance 3 │
- Instance 4 │
- Instance 5 ┘Sammlungsbasierte Parallelität - Verteile eine Sammlung auf parallele Instanzen:
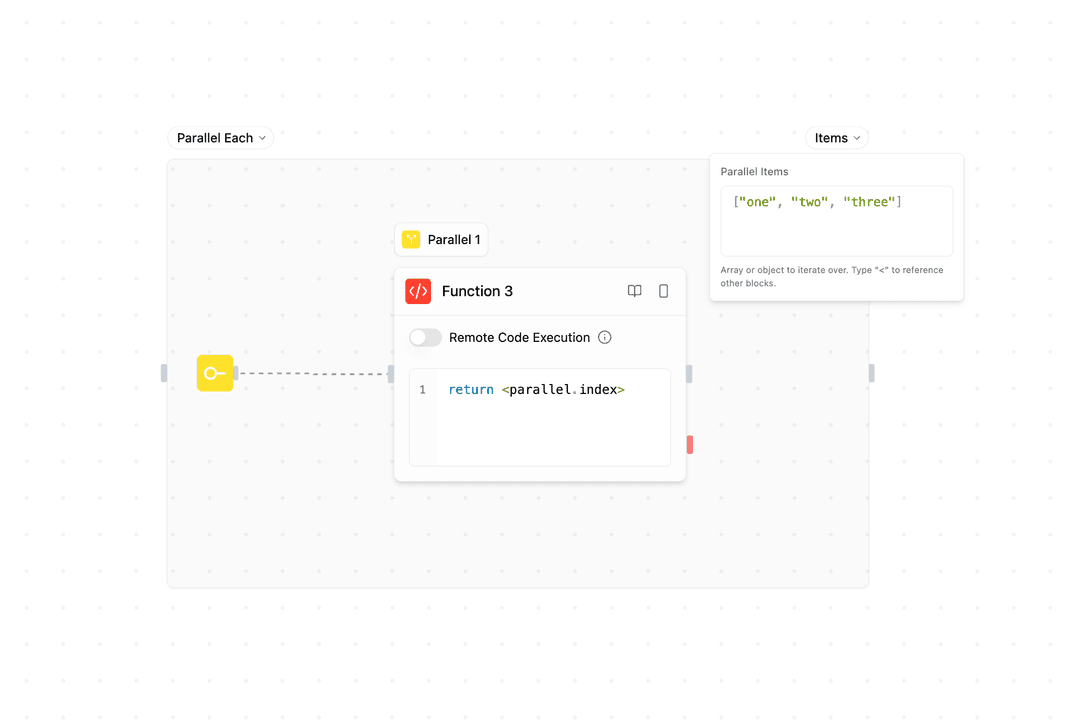
Jede Instanz verarbeitet gleichzeitig ein Element aus der Sammlung.
Example: Process ["task1", "task2", "task3"] in parallel
- Instance 1: Process "task1" ┐
- Instance 2: Process "task2" ├─ All execute simultaneously
- Instance 3: Process "task3" ┘Wie man Parallel-Blöcke verwendet
Einen Parallel-Block erstellen
- Ziehe einen Parallel-Block aus der Werkzeugleiste auf deine Leinwand
- Konfiguriere den Parallel-Typ und die Parameter
- Ziehe einen einzelnen Block in den Parallel-Container
- Verbinde den Block nach Bedarf
Auf Ergebnisse zugreifen
Nach Abschluss eines parallelen Blocks können Sie auf aggregierte Ergebnisse zugreifen:
<parallel.results>: Array mit Ergebnissen aus allen parallelen Instanzen
Beispielanwendungsfälle
Batch-API-Verarbeitung
Szenario: Mehrere API-Aufrufe gleichzeitig verarbeiten
- Paralleler Block mit einer Sammlung von API-Endpunkten
- Innerhalb des parallelen Blocks: API-Block ruft jeden Endpunkt auf
- Nach dem parallelen Block: Alle Antworten gemeinsam verarbeiten
Multi-Modell-KI-Verarbeitung
Szenario: Antworten von mehreren KI-Modellen erhalten
- Sammlungsbasierte Parallelverarbeitung über eine Liste von Modell-IDs (z.B. ["gpt-4o", "claude-3.7-sonnet", "gemini-2.5-pro"])
- Innerhalb des parallelen Blocks: Das Modell des Agenten wird auf das aktuelle Element aus der Sammlung gesetzt
- Nach dem parallelen Block: Vergleichen und Auswählen der besten Antwort
Erweiterte Funktionen
Ergebnisaggregation
Ergebnisse aus allen parallelen Instanzen werden automatisch gesammelt:
// In a Function block after the parallel
const allResults = input.parallel.results;
// Returns: [result1, result2, result3, ...]Instanzisolierung
Jede parallele Instanz läuft unabhängig:
- Separate Variablenbereiche
- Kein gemeinsamer Zustand zwischen Instanzen
- Fehler in einer Instanz beeinflussen andere nicht
Einschränkungen
Container-Blöcke (Schleifen und Parallele) können nicht ineinander verschachtelt werden. Das bedeutet:
- Sie können keinen Schleifenblock in einen parallelen Block platzieren
- Sie können keinen weiteren parallelen Block in einen parallelen Block platzieren
- Sie können keinen Container-Block in einen anderen Container-Block platzieren
Parallele Blöcke können nur einen einzigen Block enthalten. Sie können nicht mehrere Blöcke haben, die innerhalb eines parallelen Blocks miteinander verbunden sind - in diesem Fall würde nur der erste Block ausgeführt werden.
Obwohl die parallele Ausführung schneller ist, sollten Sie Folgendes beachten:
- API-Ratenbegrenzungen bei gleichzeitigen Anfragen
- Speichernutzung bei großen Datensätzen
- Maximum von 20 gleichzeitigen Instanzen, um Ressourcenerschöpfung zu vermeiden
Parallel vs. Loop
Verstehen, wann was zu verwenden ist:
| Funktion | Parallel | Loop |
|---|---|---|
| Ausführung | Gleichzeitig | Sequentiell |
| Geschwindigkeit | Schneller für unabhängige Operationen | Langsamer, aber geordnet |
| Reihenfolge | Keine garantierte Reihenfolge | Behält Reihenfolge bei |
| Anwendungsfall | Unabhängige Operationen | Abhängige Operationen |
| Ressourcennutzung | Höher | Niedriger |
Eingaben und Ausgaben
Parallel-Typ: Wählen Sie zwischen 'count' oder 'collection'
Count: Anzahl der auszuführenden Instanzen (anzahlbasiert)
Collection: Array oder Objekt zur Verteilung (sammlungsbasiert)
parallel.currentItem: Element für diese Instanz
parallel.index: Instanznummer (0-basiert)
parallel.items: Vollständige Sammlung (sammlungsbasiert)
parallel.results: Array aller Instanzergebnisse
Access: Verfügbar in Blöcken nach dem Parallel
Best Practices
- Nur unabhängige Operationen: Stellen Sie sicher, dass Operationen nicht voneinander abhängen
- Rate-Limits berücksichtigen: Fügen Sie Verzögerungen oder Drosselungen für API-intensive Workflows hinzu
- Fehlerbehandlung: Jede Instanz sollte ihre eigenen Fehler angemessen behandeln